Types of knowledge in Software Engineering

A decent engineer should be able to differentiate the types of knowledge they’ll be acquiring throughout their research/learning time. Here is my take on it, based on what I know and encountered when I was researching OAuth.
Facts#
Facts are the absolute truth and are always right.
But sometimes even the inventor of a technology couldn’t condense the fact into the docs. Things he/she thought is true might not actually be true. Though it happens only on some occasions, everyone should always take things with a grain of salt, which leads to the…
Original knowledge#
Original knowledge are things that the original creator says that they’re true. For example, if they say it is blazingly fast, then indeed it is. 🐧
Original knowledge ranges from the original documentation to the Request For Comment (RFC). Anything authoritative from credible sources is considered original knowledge. It is most of the time the correct place to look for answers, but if there is no answer to the problem one’s searching for, then it gets a little bit more tricky.
Speculation knowledge#
Suppose there is a problem that no one has ever solved. They seek help from StackOverflow, and some hospitable people on SO came and authored a genius solution. Sometimes it is indeed, but you might have already figured out that I lied about the former if you’re a seasoned engineer.
Speculation knowledge are things people come up with. By people I mean the people who have not comprehended the entirety of the problem but still came up with an answer decent enough that makes a portion of people think that it is correct.
The problem with this type of knowledge is that it is not necessary the right answer or solution, but it is sometimes so widespread that it is believed to be true. For example:
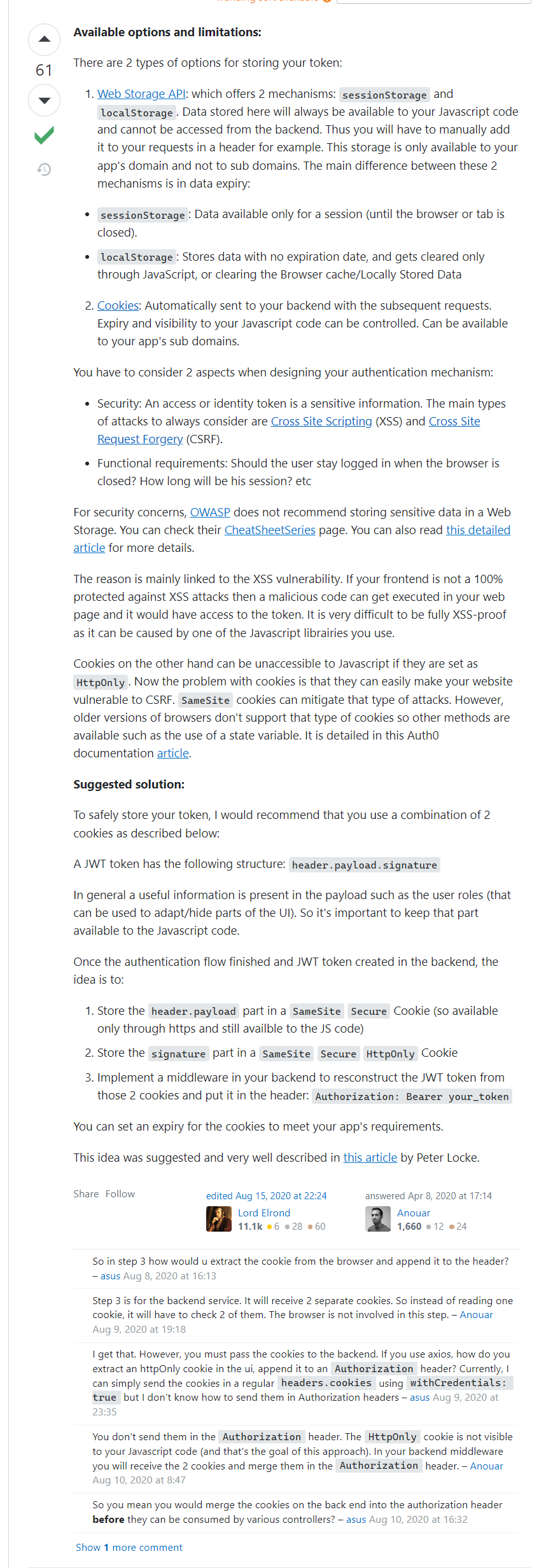
It’s gotten some hefty upvotes eh?
There are some words that are present in the proposed solution: “recommend” and “suggested”. That’s why this kind of solution is considered, in my opinion, speculation.
(Technical warning) To be clear, there is nothing wrong with the solution. It works if the Access Token cookie is set by the backend which also serves API endpoints. But what if it doesn’t? If the OP suddenly wants to “Login with Google”, so the server which spits out the Access Token cookie is Google, and the backend is homemade, then how does the backend access the cookie? Certainly, the solution only applies to a very specific scenario, and it is not clearly highlighted: the exact scenario is not mentioned in the solution, and there is no mention of any alternatives.
Adding some significant upvotes and you have a popular speculation knowledge. This is kind of a no-brainer, but do your research before applying blindly.
Inferred knowledge#
Inferred knowledge are things an engineer considered correct but no one has ever told them so. It’s mostly intuition, and it might be correct. For something to be “correct” takes some validation and sometimes opinion, but if the knowledge turns out to be a misunderstanding assumption, then the knowledge serves very little purpose.
For example, based on what you know from a book from college about how a CPU does its caching, you can infer that your CPU also does the same thing. But it is an assumption because no one has ever told you that your exact model of CPU does the same method of caching. The assumption might be correct, but to be sure, you have to dig much deeper than widespread knowledge.
Making assumptions about how things work is a very normal engineer’s thing to do. But the truth is sometimes not that trivial. Really dig deep into the truth. That is what really separates an engineer from a normie (seriously.)